

What ought to we make of huge language fashions (LLMs)? It’s fairly actually a billion-dollar query.
It’s one addressed this week in an evaluation by former OpenAI worker Leopold Aschenbrenner, during which he makes the case that we could also be only some years away from giant language model-based basic intelligence that may be a “drop-in distant employee” that may do any process human distant staff do. (He thinks that we have to push forward and construct it in order that China doesn’t get there first.)
His (very lengthy however price studying) evaluation is an effective encapsulation of 1 strand of eager about giant language fashions like ChatGPT: that they’re a larval type of synthetic basic intelligence (AGI) and that as we run bigger and bigger coaching runs and be taught extra about methods to fine-tune and immediate them, their infamous errors will largely go away.
It’s a view typically glossed as “scale is all you want,” that means extra coaching knowledge and extra computing energy. GPT-2 was not superb, however then the larger GPT-3 was a lot better, the even greater GPT-4 is best but, and our default expectation should be that this development will proceed. Have a grievance that giant language fashions merely aren’t good at one thing? Simply wait till we’ve an even bigger one. (Disclosure: Vox Media is one in all a number of publishers that has signed partnership agreements with OpenAI. Our reporting stays editorially unbiased.)
Among the many most distinguished skeptics of this angle are two AI specialists who in any other case not often agree: Yann LeCun, Fb’s head of AI analysis, and Gary Marcus, an NYU professor and vocal LLM skeptic. They argue that a few of the flaws in LLMs — their problem with logical reasoning duties, their tendency towards “hallucinations” — aren’t vanishing with scale. They anticipate diminishing returns from scale sooner or later and say we in all probability received’t get to totally basic synthetic intelligence by simply doubling down on our present strategies with billions extra {dollars}.
Who’s proper? Actually, I feel each side are wildly overconfident.
Scale does make LLMs loads higher at a variety of cognitive duties, and it appears untimely and typically willfully ignorant to declare that this development will all of a sudden cease. I’ve been reporting on AI for six years now, and I maintain listening to skeptics declare that there’s some easy process LLMs are unable to do and can by no means be capable to do as a result of it requires “true intelligence.” Like clockwork, years (or typically simply months) later, somebody figures out methods to get LLMs to do exactly that process.
I used to listen to from specialists that programming was the sort of factor that deep studying might by no means be used for, and it’s now one of many strongest facets of LLMs. Once I see somebody confidently asserting that LLMs can’t do some complicated reasoning process, I bookmark that declare. Fairly typically, it instantly seems that GPT-4 or its top-tier opponents can do it in any case.
I have a tendency to seek out the skeptics considerate and their criticisms cheap, however their decidedly blended monitor report makes me suppose they need to be extra skeptical about their skepticism.
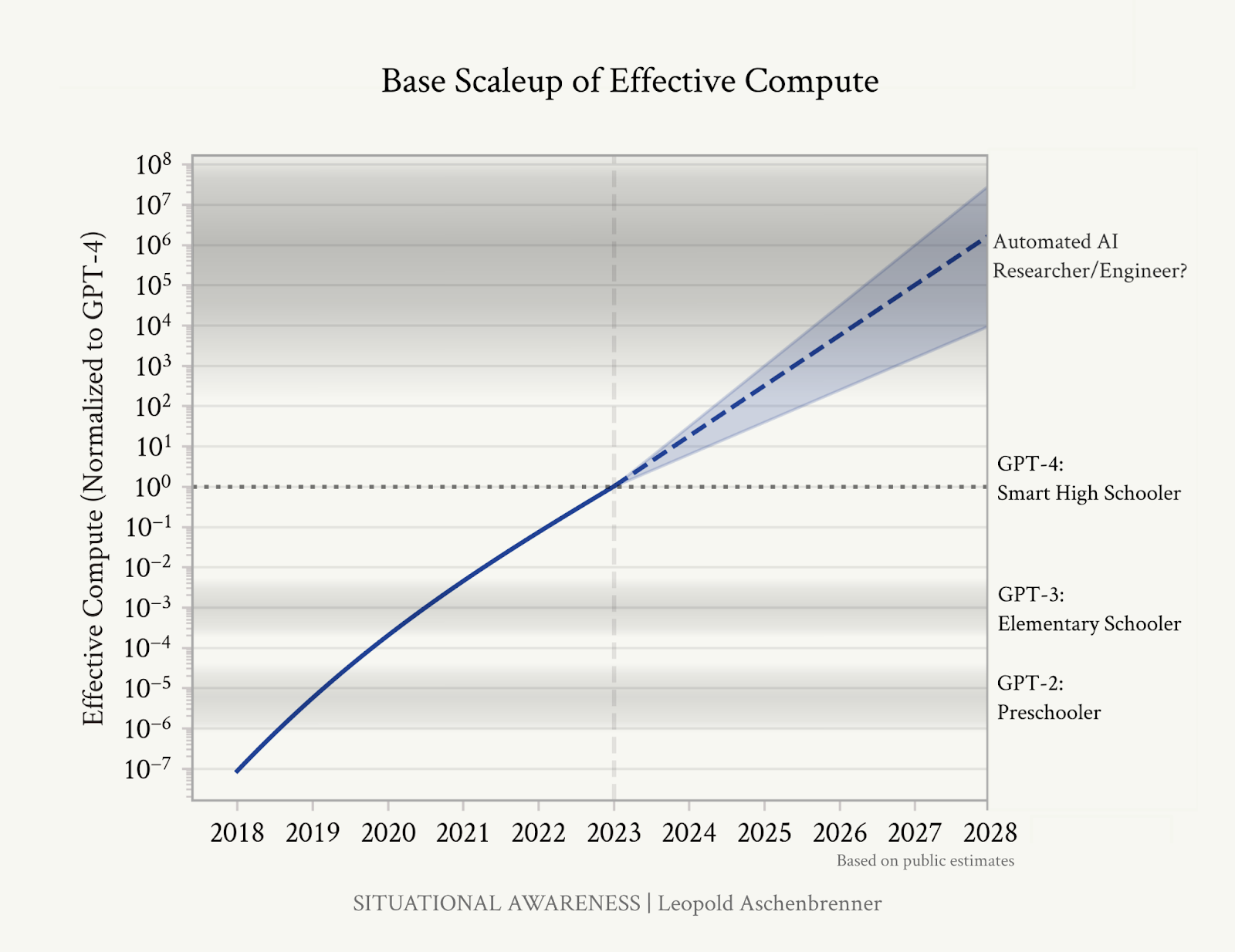
As for the individuals who suppose it’s fairly possible we’ll have synthetic basic intelligence inside a number of years, my intuition is that they, too, are overstating their case. Aschenbrenner’s argument options the next illustrative graphic:
{kind=link}
I don’t wish to wholly malign the “straight strains on a graph” method to predicting the longer term; at minimal, “present traits proceed” is at all times a chance price contemplating. However I do wish to level out (and different critics have as nicely) that the right-hand axis right here is … fully invented.
GPT-2 is in no respects significantly equal to a human preschooler. GPT-3 is far a lot better than elementary schoolers at most tutorial duties and, after all, a lot worse than them at, say, studying a brand new talent from a number of exposures. LLMs are typically deceptively human-like of their conversations and engagements with us, however they’re basically not very human; they’ve totally different strengths and totally different weaknesses, and it’s very difficult to seize their capabilities by straight comparisons to people.
Moreover, we don’t actually have any thought the place on this graph “automated AI researcher/engineer” belongs. Does it require as many advances as going from GPT-3 to GPT-4? Twice as many? Does it require advances of the type that didn’t significantly occur once you went from GPT-3 to GPT-4? Why place it six orders of magnitude above GPT-4 as a substitute of 5, or seven, or 10?
“AGI by 2027 is believable … as a result of we’re too ignorant to rule it out … as a result of we do not know what the space is to human-level analysis on this graph’s y-axis,” AI security researcher and advocate Eliezer Yudkowsky responded to Aschenbrenner.
That’s a stance I’m much more sympathetic to. As a result of we’ve little or no understanding of which issues larger-scale LLMs might be able to fixing, we will’t confidently declare robust limits on what they’ll be capable to do earlier than we’ve even seen them. However which means we can also’t confidently declare capabilities they’ll have.
Prediction is difficult — particularly concerning the future
Anticipating the capabilities of applied sciences that don’t but exist is very tough. Most individuals who’ve been doing it over the previous couple of years have gotten egg on their face. For that cause, the researchers and thinkers I respect essentially the most have a tendency to emphasise a variety of potentialities.
Possibly the huge enhancements basically reasoning we noticed between GPT-3 and GPT-4 will maintain up as we proceed to scale fashions. Possibly they received’t, however we’ll nonetheless see huge enhancements within the efficient capabilities of AI fashions because of enhancements in how we use them: determining programs for managing hallucinations, cross-checking mannequin outcomes, and higher tuning fashions to provide us helpful solutions.
Possibly we’ll construct typically clever programs which have LLMs as a part. Or perhaps OpenAI’s hotly anticipated GPT-5 might be an enormous disappointment, deflating the AI hype bubble and leaving researchers to determine what commercially precious programs could be constructed with out huge enhancements on the quick horizon.
Crucially, you don’t have to imagine that AGI is probably going coming in 2027 to imagine that the likelihood and surrounding coverage implications are price taking severely. I feel that the broad strokes of the situation Aschenbrenner outlines — during which an AI firm develops an AI system it might use to aggressively additional automate inside AI analysis, resulting in a world during which small numbers of individuals wielding huge numbers of AI assistants and servants can pursue world-altering tasks at a velocity that doesn’t allow a lot oversight — is an actual and scary chance. Many individuals are spending tens of billions of {dollars} to deliver that world about as quick as doable, and lots of of them suppose it’s on the close to horizon.
That’s price a substantive dialog and substantive coverage response, even when we predict these main the best way on AI are too certain of themselves. Marcus writes of Aschenbrenner — and I agree — that “in case you learn his manuscript, please learn it for his considerations about our underpreparedness, not for his sensationalist timelines. The factor is, we must be nervous, irrespective of how a lot time we’ve.”
However the dialog might be higher, and the coverage response extra appropriately tailor-made to the scenario, if we’re candid about how little we all know — and if we take that confusion as an impetus to get higher at measuring and predicting what we care about in relation to AI.
A model of this story initially appeared within the Future Good e-newsletter. Join right here!