

In “SQL: The Common Solvent for REST APIs” we noticed how Steampipe’s suite of open supply plug-ins that translate REST API calls immediately into SQL tables. These plug-ins had been, till lately, tightly certain to the open supply engine and to the occasion of Postgres that it launches and controls. That led members of the Steampipe neighborhood to ask: “Can we use the plug-ins in our personal Postgres databases?” Now the reply is sure—and extra—however let’s concentrate on Postgres first.

{kind=link}
Utilizing a Steampipe Plugin as a Standalone Postgres International Information Wrapper (FDW)
Go to Steampipe downloads to search out the installer on your OS, and run it to accumulate the Postgres FDW distribution of a plugin—on this case, the GitHub plugin. It’s one in all (presently) 140 plug-ins out there on the Steampipe hub. Every plugin gives a set of tables that map API calls to database tables—within the case of the GitHub plugin, 55 such tables. Every desk can seem in a FROM or JOIN clause; right here’s a question to pick columns from the GitHub challenge, filtering on a repository and writer.
choose
state,
updated_at,
title,
url
from
github_issue
the place
repository_full_name="turbot/steampipe"
and author_login = 'judell'
order by
updated_at descFor those who’re utilizing Steampipe, you may set up the GitHub plugin like this:
steampipe plugin set up githubthen run the question within the Steampipe CLI or in any Postgres consumer that may hook up with Steampipe’s occasion of Postgres.
However if you wish to do the identical factor in your individual occasion of Postgres, you may set up the plugin differently.
$ sudo /bin/sh -c "$(
curl -fsSL https://steampipe.io/set up/postgres.sh)"
Enter the plugin title: github
Enter the model (newest):
Found:
- PostgreSQL model: 14
- PostgreSQL location: /usr/lib/postgresql/14
- Working system: Linux
- System structure: x86_64
Based mostly on the above, steampipe_postgres_github.pg14.linux_amd64.tar.gz
will probably be downloaded, extracted and put in at: /usr/lib/postgresql/14
Proceed with putting in Steampipe PostgreSQL FDW for model 14 at
/usr/lib/postgresql/14?
- Press 'y' to proceed with the present model.
- Press 'n' to customise your PostgreSQL set up listing
and choose a unique model. (Y/n):
Downloading steampipe_postgres_github.pg14.linux_amd64.tar.gz...
###############################################################
############################ 100.0%
steampipe_postgres_github.pg14.linux_amd64/
steampipe_postgres_github.pg14.linux_amd64/steampipe_postgres_
github.so
steampipe_postgres_github.pg14.linux_amd64/steampipe_postgres_
github.management
steampipe_postgres_github.pg14.linux_amd64/steampipe_postgres_
github--1.0.sql
steampipe_postgres_github.pg14.linux_amd64/set up.sh
steampipe_postgres_github.pg14.linux_amd64/README.md
Obtain and extraction accomplished.
Putting in steampipe_postgres_github in /usr/lib/postgresql/14...
Efficiently put in steampipe_postgres_github extension!
Information have been copied to:
- Library listing: /usr/lib/postgresql/14/lib
- Extension listing: /usr/share/postgresql/14/extension/Now hook up with your server as typical, utilizing psql or one other consumer, most sometimes because the postgres person. Then run these instructions, that are typical for any Postgres international information wrapper. As with all Postgres extensions, you begin like this:
CREATE EXTENSION steampipe_postgres_fdw_github;To make use of a international information wrapper, you first create a server:
CREATE SERVER steampipe_github FOREIGN DATA WRAPPER
steampipe_postgres_github OPTIONS (config 'token="ghp_..."');Use OPTIONS to configure the extension to make use of your GitHub entry token. (Alternatively, the usual setting variables used to configure a Steampipe plugin—it’s simply GITHUB_TOKEN on this case—will work for those who set them earlier than beginning your occasion of Postgres.)
The tables offered by the extension will dwell in a schema, so outline one:
CREATE SCHEMA github;Now import the schema outlined by the international server into the native schema you simply created:
IMPORT FOREIGN SCHEMA github FROM SERVER steampipe_github INTO github;Now run a question!
The international tables offered by the extension dwell within the github schema, so by default you’ll consult with tables like github.github_my_repository. For those who set search_path="github", although, the schema turns into elective and you may write queries utilizing unqualified desk names. Right here’s a question we confirmed final time. It makes use of the GitHub_search_repository which encapsulates the GitHub API for looking out repositories.
Suppose you’re searching for repos associated to PySpark. Right here’s a question to search out repos whose names match “pyspark” and report a number of metrics that can assist you gauge exercise and recognition.
choose
name_with_owner,
updated_at, -- how lately up to date?
stargazer_count -- how many individuals starred the repo?
from
github_search_repository
the place
question = 'pyspark in:title'
order by
stargazer_count desc
restrict 10;
+---------------------------------------+------------+---------------+
|name_with_owner |updated_at |stargazer_count|
+---------------------------------------+------------+---------------+
| AlexIoannides/pyspark-example-project | 2024-02-09 | 1324 |
| mahmoudparsian/pyspark-tutorial | 2024-02-11 | 1077 |
| spark-examples/pyspark-examples | 2024-02-11 | 1007 |
| palantir/pyspark-style-guide | 2024-02-12 | 924 |
| pyspark-ai/pyspark-ai | 2024-02-12 | 791 |
| lyhue1991/eat_pyspark_in_10_days | 2024-02-01 | 719 |
| UrbanInstitute/pyspark-tutorials | 2024-01-21 | 400 |
| krishnaik06/Pyspark-With-Python | 2024-02-11 | 400 |
| ekampf/PySpark-Boilerplate | 2024-02-11 | 388 |
| commoncrawl/cc-pyspark | 2024-02-12 | 361 |
+---------------------------------------+------------+---------------+If in case you have quite a lot of repos, the primary run of that question will take a number of seconds. The second run will return outcomes immediately, although, as a result of the extension features a highly effective and complex cache.
And that’s all there’s to it! Each Steampipe plugin is now additionally a international information wrapper that works precisely like this one. You’ll be able to load a number of extensions to be able to be part of throughout APIs. In fact, you may be part of any of those API-sourced international tables with your individual Postgres tables. And to avoid wasting the outcomes of any question, you may prepend “create desk NAME as” or “create materialized view NAME as” to a question to persist outcomes as a desk or view.
Utilizing a Steampipe Plugin as a SQLite Extension That Offers Digital Tables
Go to Steampipe downloads to search out the installer on your OS and run it to accumulate the SQLite distribution of the identical plugin.
$ sudo /bin/sh -c "$(curl -fsSL https://steampipe.io/set up/sqlite.sh)"
Enter the plugin title: github
Enter model (newest):
Enter location (present listing):
Downloading steampipe_sqlite_github.linux_amd64.tar.gz...
############################################################
################ 100.0%
steampipe_sqlite_github.so
steampipe_sqlite_github.linux_amd64.tar.gz downloaded and
extracted efficiently at /dwelling/jon/steampipe-sqlite.Right here’s the setup, and you may place this code in ~/.sqliterc if you wish to run it each time you begin sqlite.
.load /dwelling/jon/steampipe-sqlite/steampipe_sqlite_github.so
choose steampipe_configure_github('
token="ghp_..."
');Now you may run the identical question as above. Right here, too, the outcomes are cached, so a second run of the question will probably be on the spot.
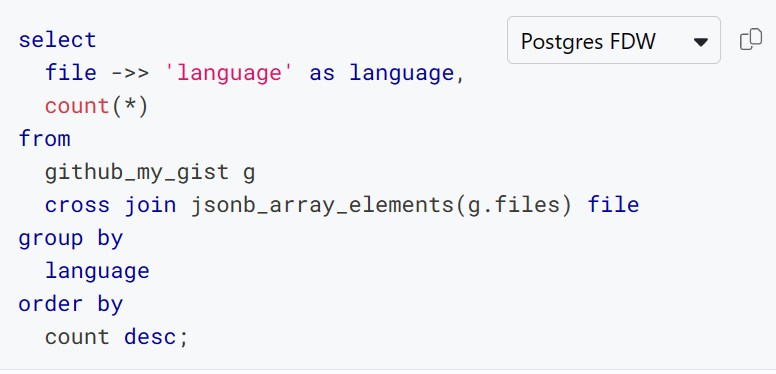
What concerning the variations between Postgres-flavored and SQLite-flavored SQL? The Steampipe hub is your buddy! For instance, listed here are Postgres and SQLite variants of a question that accesses a subject inside a JSON column to be able to tabulate the languages related together with your gists.
Postgres
SQLite
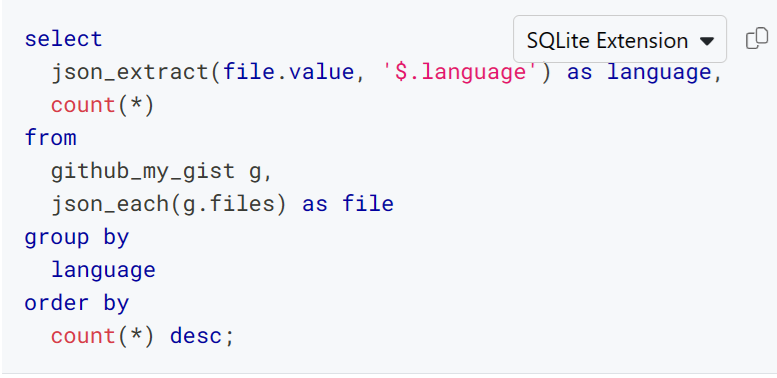
The github_my_gist desk stories particulars about gists that belong to the GitHub person who’s authenticated to Steampipe. The language related to every gist lives in a JSONB column known as recordsdata, which accommodates a listing of objects like this.
{
"measurement": 24541,
"sort": "textual content/markdown",
"raw_url": "https://gist.githubusercontent.com/judell/49d66ca2a5d2a3b
"filename": "steampipe-readme-update.md",
"language": "Markdown"
}The capabilities wanted to venture that checklist as rows differ: in Postgres you employ jsonb_array_elements and in SQLite it’s json_each.
As with Postgres extensions, you may load a number of SQLite extensions to be able to be part of throughout APIs. You’ll be able to be part of any of those API-sourced international tables with your individual SQLite tables. And you’ll prepend create desk NAME as to a question to persist outcomes as a desk.
Utilizing a Steampipe Plugin as a Standalone Export Software
Go to Steampipe downloads to search out the installer on your OS, and run it to accumulate the export distribution of a plugin—once more, we’ll illustrate utilizing the GitHub plugin.
$ sudo /bin/sh -c "$(curl -fsSL https://steampipe.io/set up/export.sh)"
Enter the plugin title: github
Enter the model (newest):
Enter location (/usr/native/bin):
Created short-term listing at /tmp/tmp.48QsUo6CLF.
Downloading steampipe_export_github.linux_amd64.tar.gz...
##########################################################
#################### 100.0%
Deflating downloaded archive
steampipe_export_github
Putting in
Making use of needed permissions
Eradicating downloaded archive
steampipe_export_github was put in efficiently to
/usr/native/bin
$ steampipe_export_github -h
Export information utilizing the github plugin.
Discover detailed utilization data together with desk names,
column names, and examples on the Steampipe Hub:
https://hub.steampipe.io/plugins/turbot/github
Utilization:
steampipe_export_github TABLE_NAME [flags]
Flags:
--config string Config file information
-h, --help assist for steampipe_export_github
--limit int Restrict information
--output string Output format: csv, json or jsonl
(default "csv")
--select strings Column information to show
--where stringArray the place clause informationThere’s no SQL engine within the image right here; this software is solely an exporter. To export all of your gists to a JSON file:
steampipe_export_github github_my_gist --output json > gists.jsonTo pick out just some columns and export to a CSV file:
steampipe_export_github github_my_gist --output csv --select
"description,created_at,html_url" > gists.csvYou need to use --limit to restrict the rows returned and --where to filter them, however largely you’ll use this software to rapidly and simply seize information that you simply’ll therapeutic massage elsewhere, for instance, in a spreadsheet.
Faucet into the Steampipe Plugin Ecosystem
Steampipe plug-ins aren’t simply uncooked interfaces to underlying APIs. They use tables to mannequin these APIs in helpful methods. For instance, the github_my_repository desk exemplifies a design sample that applies persistently throughout the suite of plug-ins. From the GitHub plugin’s documentation:
You’ll be able to personal repositories individually, or you may share possession of repositories with different individuals in a corporation. The
github_my_repositorydesk will checklist repos that you simply personal, that you simply collaborate on, or that belong to your organizations. To question ANY repository, together with public repos, use thegithub_repositorydesk.
Different plug-ins observe the identical sample. For instance, the Microsoft 365 plugin gives each microsoft_my_mail_message and microsoft_mail_message, and the plugin gives googleworkspace_my_gmail_message and googleworkspace_gmail. The place doable, plug-ins consolidate views of sources from the attitude of an authenticated person.
Whereas plug-ins sometimes present tables with fastened schemas, that’s not at all times the case. Dynamic schemas, carried out by the Airtable, CSV, Kubernetes, and Salesforce plug-ins (amongst others) are one other key sample. Right here’s a CSV instance utilizing a standalone Postgres FDW.
IMPORT FOREIGN SCHEMA csv FROM SERVER steampipe_csv INTO csv
OPTIONS(config 'paths=["/home/jon/csv"]');Now all of the .csv recordsdata in /dwelling/jon/csv will automagically be Postgres international tables. Suppose you retain monitor of legitimate homeowners of EC2 situations in a file known as ec2_owner_tags. Right here’s a question in opposition to the corresponding desk.
choose * from csv.ec2_owner_tags;
proprietor | _ctx
----------------+----------------------------
Pam Beesly | {"connection_name": "csv"}
Dwight Schrute | {"connection_name": "csv"}You possibly can be part of that desk with the AWS plugin’s aws_ec2_instance desk to report proprietor tags on EC2 situations which are (or are usually not) listed within the CSV file.
choose
ec2.proprietor,
case
when csv.proprietor is null then 'false'
else 'true'
finish as is_listed
from
(choose distinct tags ->> 'proprietor' as proprietor
from aws.aws_ec2_instance) ec2
left be part of
csv.ec2_owner_tags csv on ec2.proprietor = csv.proprietor;
proprietor | is_listed
----------------+-----------
Dwight Schrute | true
Michael Scott | falseThroughout the suite of plug-ins there are greater than 2,300 predefined fixed-schema tables that you should use in these methods, plus an infinite variety of dynamic tables. And new plug-ins are consistently being added by Turbot and by Steampipe’s open supply neighborhood. You’ll be able to faucet into this ecosystem utilizing Steampipe or Turbot Pipes, from your individual Postgres or SQLite database, or immediately from the command line.